By Douglas L. Beck and Lauren Benitez
This article is a part of the May/June 2019, Volume 31, Number 3, Audiology Today issue.
Hearing-care professionals (HCPs) and hearing aid wearers report the chief complaint secondary to hearing loss and to wearing traditional hearing aids, is the inability to understand speech-in-noise (SIN; see Beck et al, 2019). Beck et al (2018) reported that, in addition to the 37 million Americans with audiometric hearing loss, 26 million have hearing difficulty and/or difficulty understanding SIN, despite clinically normal thresholds. As such, helping people hear (i.e., to perceive sound) and helping people listen (i.e., to comprehend, or apply meaning to sound) remains paramount.
Many excellent SIN tests are commercially available (see Wilson et al, 2007 for a review). Nonetheless, despite the fact that the American Academy of Audiology (Academy) and the American Speech–Language–Hearing Association (ASHA) Best Practice (BP) statements recommend SIN testing, it appears that fewer than 15 percent of audiologists perform SIN tests routinely (Beck, 2017; Clark, 2017). It is unclear why SIN testing is not applied universally. Perhaps the associated acquisition costs, the negligible reimbursement rates, and/or the administration time impede their clinical use?
Regardless, we believe a SIN score acquired on an individual, regardless of his or her audiogram, represents the single most important measure of auditory function. Unaided and aided SIN scores not only reflect the reason the patient sought help (i.e., the unaided SIN score) but also indicate how much help he or she has received through amplification (i.e., the aided SIN score). In this article, we will outline a SIN protocol that may be free or relatively inexpensive (depending on the equipment you already own, and the cost of calibration).
Our SIN protocol takes less than 120 seconds to administer and is quick, reliable, and clinically useful. In addition, we will present pilot data acquired on eight individuals with and without audiometric hearing loss, and we will offer some calibration guidelines (Appendix).
Background
Jerger (2018) recently reviewed two important articles from the 1940s. The Harvard Report (1946) indicated monosyllabic word testing has “rather low reliability” even when carefully standardized. The Harvard Report suggested that measuring the signal-to-noise ratio (SNR, the level difference required for speech to be comprehended in a background of noise) was an intriguing idea. Jerger reflected favorably on The Harvard Report for indicating that an SNR measure would be a better metric reflecting individual differences in challenging acoustic environments. Carhart (1946) also indicated clear benefits associated with obtaining an SNR measure to reflect speech understanding in difficult noisy situations.
An individual’s SIN performance cannot be reliably predicted from his or her speech-in-quiet (SIQ) performance. That is, knowing that a person has excellent word recognition in quiet using monosyllabic words (such as the NU-6, or the CID W-22 word lists) simply does not indicate how the individual will perform in speech babble.
Wilson (2011) evaluated 3,430 veterans and reported SIN scores cannot be predicted based on an audiogram, and word recognition in quiet does not predict SIN ability. Therefore, the audiologist should establish/quantify the degree of SIN impairment (as indicated by the SNR-50, see below). Of note, a group of individuals with mild–moderate sensorineural hearing loss (SNHL) is likely to have a broad range of SIN abilities, which interestingly, may be analogous to the range of people with normal pure-tone thresholds (Vermiglio et al, 2012; Vermiglio et al, 2019).
Improving SIN ability generally is accomplished through an improved SNR. Indeed, familiar technologies including adaptive and nonadaptive directional microphones, beam-forming microphones, and various adaptive and nonadaptive noise-reduction protocols and algorithms have been incorporated into hearing aids to essentially improve the SNR, thereby improving the wearer’s SIN ability.
SNR-50
The SNR required to obtain a score of 50 percent correct is referred to (throughout this article) as the “SNR-50.” Of note, establishing the SNR-50 (in this protocol) is very similar to obtaining a pure-tone threshold. The primary speech signal is held constant at the most comfortable loudness (MCL) while four-talker speech babble ascends and descends. The SNR-50 is established when the subject repeats half of the target words (50 percent) correctly. However, instead of 5- and 10-dB steps (as prescribed for pure-tone thresholds), we use 1- and 2-dB steps to rapidly acquire a repeatable SNR-50.
With regard to the QuickSIN, Killion (2002) reported adults with normal hearing needed an average SNR-50 of 2 dB to repeat 50 percent of the words correctly, and people with mild–moderate SNHL required an average SNR-50 of 8 dB. These same values offer guidance as to expected SNR-50s in this pilot study. Dillion (2012) reported that for every 10 dB of hearing loss, the subject requires an additional 1–3 dB of SNR to maintain their unaided intelligibility.
| 250 Hz (25 dB) |
| 500 Hz (25 dB) |
| 750 Hz (25 dB) |
| 1000 Hz 25 dB) |
| 1,500 Hz (30 dB) |
| 2,000 Hz (30 dB) |
| 3,000 Hz (30 dB) |
| 4,000 Hz (35 dB) |
| 6,000 Hz (35 dB) |
| 8,000 Hz (25 dB) |
SNR-50 Examples
Given a primary speech message originating in front of a listener at 70 dB SPL, a person with normal hearing and normal listening ability might be expected to repeat half the words correctly in the presence of a 68 dB four-talker babble originating behind the listener. Further, a listener with a mild–moderate SNHL, given the same speech signal of 70 dB SPL, would likely require an 8-dB SNR (babble at 62 dB SPL) to repeat 50 percent of the words correctly. To be clear, the relationship between pure-tone thresholds and SIN ability is highly variable and not predictable.
SIN and SNR-50 Pearls
#1
The anticipated SNR-50 values described here (2 dB for people with hearing within normal limits; 8 dB for people with mild-moderate SNHL) are estimates and serve as guidelines only. Each person must be tested to determine his or her SNR-50 unaided and in the sound field. Local normative values should be established for each test facility after proper calibration, to be sure results are in alignment with generally accepted values. Of note, we do not recommend using headphones or insert earphones as our goal is to replicate, as best we can, the real-world difficulty experienced in cocktail parties, restaurants, and similar acoustically challenging situations. Therefore, a calibrated sound-field test is required.
#2
We recommend four-talker speech babble rather than speech-spectrum noise, white noise, pink noise, etc. Artificial noises do not contain linguistic information, and therefore, artificial noises may be easier to ignore. However, some people do perform better in four-talker babble rather than steady-state noise (Vermiglio et al, 2019). In general, we anticipate four-talker babble better replicates real-world difficulty; yet if the four-talker babble task is too difficult, we recommend switching to an artificial noise as needed for unaided and aided measures (apples to apples).
#3
We believe that if the primary goal of SIN testing is to determine the SNR-50, and the secondary goal is to select amplification, step sizes of 4 or 5 dB are too large to define subtle, yet important, differences in hearing aid benefit. That is, if hearing aids A, B, C, and D improve the SNR-50 by 1, 2, 3, and 4 dB, respectively, these would appear the same given a 5-dB step size. Of note, a 1-dB improvement in SNR may facilitate 8 percent to 10 percent improvement in word recognition (Taylor and Mueller, 2017), and is thus, important to quantify.
#4
Although we realize “speech in front” and “babble in rear” is not a realistic representation of all SIN tasks, this simple two-speaker arrangement can be easily facilitated in many sound booths and may also be set up outside the booth. That is, SIN tests are suprathreshold tests and may not require a sound booth (unless the ambient noise floor is excessively high) as long as the entire system is professionally calibrated for speech stimuli and four-talker babble (see Appendix). A simple, repeatable, “apples-to-apples” approach is advocated.
#5
We used the NU-6 word lists as our primary stimuli. However, all word lists are not necessarily equivalent regarding difficulty, audibility, vocabulary, and more. Some word lists have been found to be equivalent in quiet, but not in noise. As such, one should review the literature to choose the best primary stimuli (in any language) for their protocol and to establish their own clinical norms, in tandem with the protocol described here. Important readings on selecting and using words lists includes: Lawson (2012), Loven and Hawkins (1983), and Stockley and Green (2000). Regardless of the selected word lists, we recommend the use of digital recordings of your preferred word list and your own established clinical norms (as above), as hardware, software, protocols, word lists, and calibration protocols vary.
| SUBJECT | AGE | UNAIDED SNR-50 70 dB | P1 AIDED SNR-50 | P2 AIDED SNR-50 |
| 1 | 63 | +6 dB | +3 dB | +1 dB |
| 2 | 75 | CNT | +9 dB | +6 dB |
| 3 | 23 | +5 dB | +4 dB | +1 dB |
| 4 | 36 | +6 dB | +4 dB | +1 dB |
| 5 | 47 | +4 dB | +3 dB | +3 dB |
| 6 | 56 | +7 dB | +4 dB | +3 dB |
| 7 | 32 | +8 dB | +3 dB | +3 dB |
| 8 | 59 | +7 dB | +3 dB | +1 dB |
Speech-in-Noise Protocol
Eight adult volunteers participated in our pilot testing, with and without hearing loss. Each received otoscopy and a typical air-bone-speech evaluation. Unaided and aided sound field tests were obtained using the calibrated sound field (see Appendix). The recorded NU-6 word lists were presented through the front speaker at 70 dB SPL, and four-talker speech babble was delivered through the rear speaker. The task was explained, “Your task is to try to ignore all the voices from behind you. Please repeat the words you hear from the front speaker.”
During all SIN presentations, the front speaker loudness was held constant at 70 dB SPL, and only the rear-speaker loudness varied. Although we pre-set our front speaker to 70 dB SPL, it seems reasonable to set this to the MCL level or perhaps MCL plus 5 dB, to assure audibility (as needed), while not exceeding uncomfortable loudness (UCL) levels.
The first trial (“introductory task”) was presented with speech in the front speaker at 70 dB SPL and four-talker babble presented through the rear speaker at 55 dB SPL (15 dB SNR). This was an easy task for all participants. The introductory level allowed for a quick practice session during which we confirmed the task was understood by the listener. Of note, our protocol is similar to that used in pure-tone audiometry when bracketing thresholds. For example, using the 15 dB SNR, all participants easily got three words in a row correct.
Consequently, we reduced the SNR to 10 dB (i.e., made the babble louder by 5 dB, resulting in a 10 dB SNR), and for most people, this too, was rather easy. If the subject was only able to repeat one or two of the next three words correctly, we made the task easier by decreasing the babble by 2 dB (resulting in a 12 dB SNR) and then bracketed in 1-dB steps. The entire procedure from an introductory 15 dB SNR to their bracketed SNR-50 threshold usually involved fewer than 25 words and required less than two minutes.
In our pilot program, to avoid overamplification and uncomfortably loud presentations for people with thresholds within normal limits, we placed the following values into the Genie SoftwareTM, and programmed the Oticon Opn 1TM hearing aids using the following fictitious thresholds (all were fitted with open domes, see TABLE 1).
The first test session was accomplished with the following parameters (Program 1, aka P1):
Open Sound Transition Selected by Genie, Noise Reduction Complex, Directionality OPN, Gain Control 100% (Level 3), VAC+.
The second test session was accomplished using the same parameters, except the noise reduction was reset to maximum (Program 2, aka P2).
Note: For aided presentations, before presenting the primary-speech stimulus in front, it may be important to wait 3–5 seconds (or longer) each time the four-talker babble loudness changes, to allow the noise-reduction algorithm to activate. In our pilot test, we used Oticon Opn 1TM devices in which the noise-reduction circuit activates in less than 25 milliseconds.
Discussion
The most common complaint from people with SNHL and with traditional hearing aids is their inability to understand SIN (Beck et al, 2019). As such, obtaining a pre- and postfitting SNR-50 is important. In this article, we have demonstrated a simple protocol that can rapidly determine SIN thresholds and can be used to validate and verify important differences between unaided and aided responses. This pilot study was executed to reinforce the necessity of SIN testing and to offer a quick, inexpensive, and rational SIN protocol to help determine a patients’s unaided (baseline) and aided SIN performance, as demonstrated by their unaided and aided SNR-50.
Appendix
Equipment – MedRx Stealth or MedRx ARC with Free Field Speakers
Stimulus – NU-6 Word Lists
Babble – Auditec Speech Babble (included with all MedRx Audiometers)
Calibration – Calibrations should be performed by a trained technician with speakers at ear level. Speakers should be placed (ideally) at 0- and 180-degree azimuth at 1 meter from subject’s head. If the speakers must be moved, mark the exact location of the speakers and subject chair. Each audiometer has variable calibration protocols. MedRx audiometers must have full free-field calibrations performed for accurate speech testing. Calibration frequencies include 125–8000 Hz, white noise, speech weighted noise and speech tone.
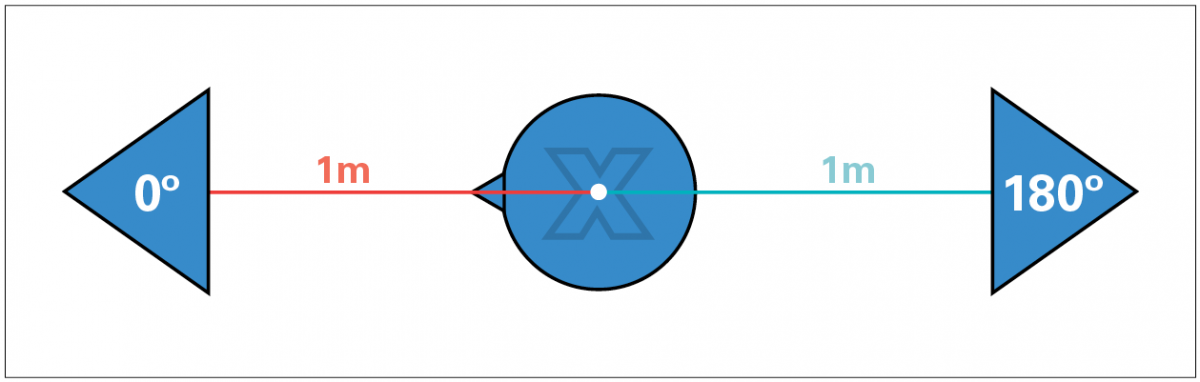
FIGURE 1. Subject and speaker diagram where X marks the placement of the calibration microphone.
To perform free-field calibration, the microphone location must estimate the center of the subject’s head position (marked by an X in Figure 1). All measurements should be made with the microphone in this static position. Set the sound level meter (SLM) to SPL mode (see FIGURE 2).
- Subject and speaker diagram where X marks the calibration microphone (FIGURE 1).
- Speakers at 0 degrees (right channel) and 180 degrees (left channel).
- MedRx free-field calibrations (completed by certified technician).
- Complete full pure-tone, free-field calibration using warble tones.
- MedRx equipment must have white noise, speech babble (A Weighted), speech-tone calibrated (1000 Hz cal. tone).
- Save calibration.
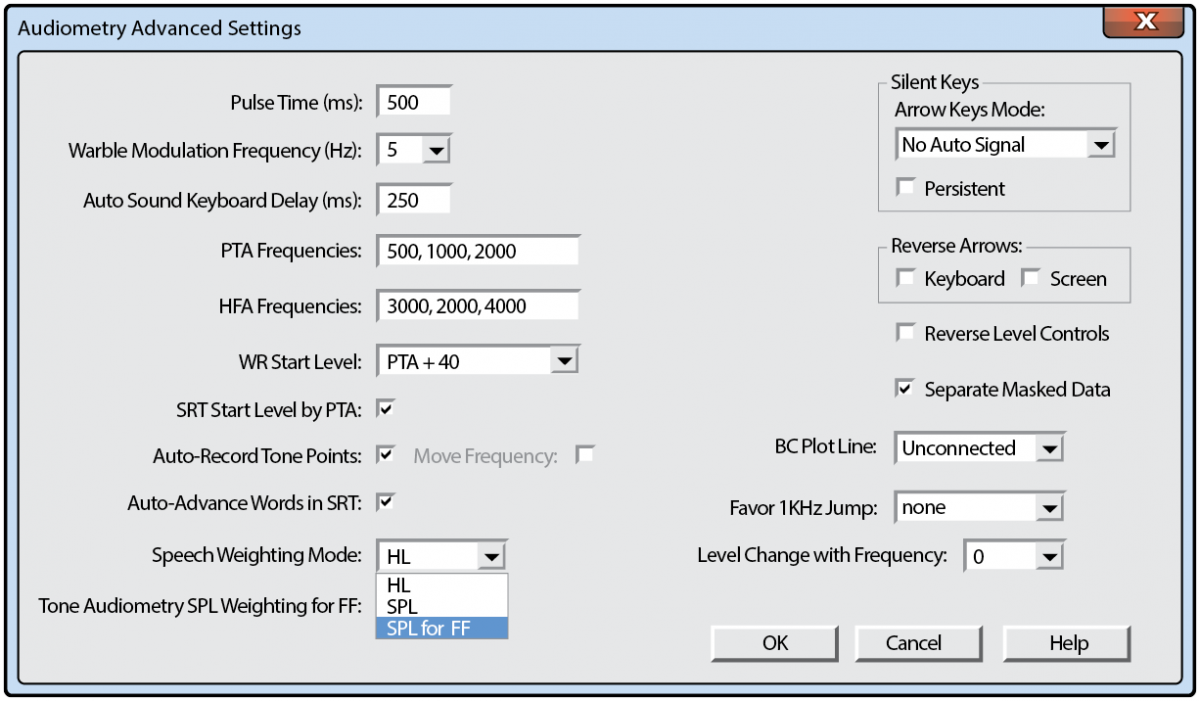
FIGURE 2. Avant advanced audiometry settings, set free field to SPL.
Special Thanks
The authors offer thanks and appreciation to Andy Vermiglio, AuD, and Caleb Sparkman, AuD, for their review and valuable input regarding the preparation of this manuscript.
References
Beck DL. (2017) Best practices in hearing aid dispensing: An interview with Michael Valente, PhD. Hear Rev 24(12):39–41.
Beck DL, Danhauer JL, Abrams HB, Atcherson SR, Brown DK, Chasin M, Clark JG, De Placido C, Edwards B, Fabry DA, Flexer C, Fligor B, Frazer G, Galster JA, Gifford L, Johnson CE, Madell J, Moore DR, Roeser RJ, Saunders GH, Searchfield GD, Spankovich C, Valente M, Wolfe J. (2018) Audiologic considerations for people with normal hearing sensitivity yet hearing difficulty and/or speech-in-noise problems. Hear Rev 25(10):28–38.
Beck DL, Ng E, Jensen JJ. (2019): A scoping review 2019: OpenSound Navigator. Hear Rev 26(2):28–31.
Clark, JG, Huff C, Earl B. (2017) Clinical practice report card–Are we meeting best practice standards for adult hearing rehabilitation? Audiol Today 29(6):15–25.
Carhart R. (1946) Tests for selection of hearing aids. Laryngoscope 56(12):780–794.
Dillon H. (2012) Hearing Aids. (2d Ed) Thieme Publishers.
The Harvard Report. (1946) Davis H, Hudgins CV, Marquis RJ, et al. The Selection of Hearing Aids. Laryngoscope 56(3):85–115.
Jerger J. (2018) Lessons from the past: Two influential articles in the early history of audiology. Hear Rev. Published Dec 5.
Killion MC. (2002) New thinking on hearing in noise: a generalized articulation index. Sem Hear 23(1):57–75.
Lawson G. (2012) Speech Audiometry, Word Recognition, and Binomial Variables: Interview with Gary Lawson. www.audiology.org/news/speech-audiometry-word-recognition-and-binomial-variables-interview-gary-lawson-phd.
Loven F, Hawkins D. (1983) Interlist equivalency of the CID W-22 word lists presented in quiet and in noise. Ear Hear 4:91–97.
Stockley KB, Green WB. (2000) Interlist equivalency of the Northwestern University auditory test No. 6 in quiet and noise with adult hearing-impaired individuals. J Am Acad Audiol 11:91–96.
Taylor B, Mueller G. (2017) Fitting and Dispensing Hearing Aids (2d ed) Plural Publishing.
Vermiglio AJ, Herring CC, Heeke P, Post CE, Fang X. (2019) Sentence recognition in steady-state speech-shaped noise versus four-talker babble. J Am Acad Audiol 30(1):54–65.
Vermiglio AJ, Soli SD, Freed DJ, Fisher LM. (2012) The relationship between high-frequency pure-tone hearing loss, hearing in noise test (HINT) thresholds, and the articulation index. J Am Acad Audiol 23(10):779–788.
Wilson RH. (2011) Clinical experience with the words-in-noise test on 3430veterans: comparisons with pure-tone thresholds and word recognition in quiet. J Am Acad Audiol 22(7):405–423.